フラットファイルスキーマ
|
DataWeave 2.1 は Mule 4.1 と互換性があります。 Mule 4.1 の標準サポートは 2020 年 11 月 2 日に終了しました。このバージョンの Mule は、拡張サポートが終了する 2022 年 11 月 2 日にそのすべてのサポートが終了します。 このバージョンの Mule を使用する CloudHub には新しいアプリケーションをデプロイできなくなります。許可されるのはアプリケーションへのインプレース更新のみになります。 標準サポートが適用されている最新バージョンの Mule 4 にアップグレードすることをお勧めします。これにより、最新の修正とセキュリティ機能強化を備えたアプリケーションが実行されます。 |
DataWeave ではさまざまな種別のデータを処理できます。このほとんどの種別で、入力構造を記述するスキーマをインポートし、設計時に価値あるメタデータにアクセスできます。
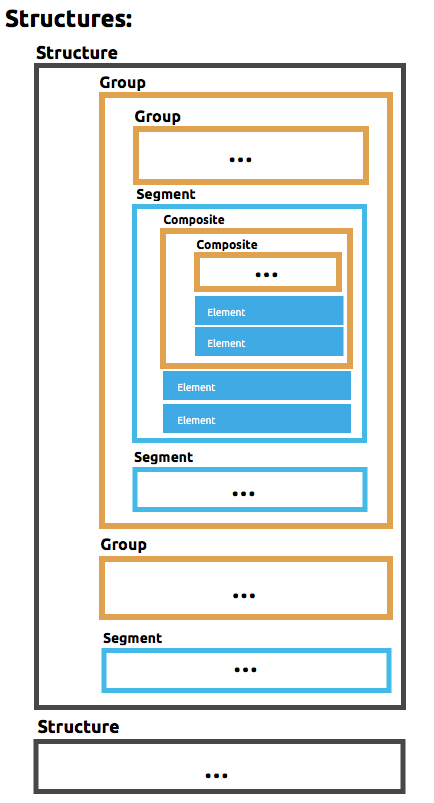
DataWeave では、フラットファイルスキーマを表す FFD (Flat File Definition) と呼ばれる YAML 形式を使用します。FFD 形式は、広範なユースケースをサポートするのに十分な柔軟姓を備え、要素、複合、セグメント、グループ、および構造の概念に基づきます。
スキーマはフラットファイルスキーマ言語で記述する必要があり、慣例により .ffs 拡張子を使用します。この言語は、Anypoint Studio でも受け入れることができる EDI スキーマ言語 (ESL) によく似ています。
DataWeave では、プロパティを使用して入力または出力をフラットファイルスキーマにバインドできます。
固定幅の簡単な形式を使用する場合、Fixed Width 型を使用してデータ型を Transform コンポーネントから直接セットアップできます。Studio でこの型のインスタンスを作成すると、一致するスキーマ定義が自動的に生成されます。
スキーマ内のコンポーネントの種別
フラットファイルスキーマを構成するさまざまな種別のコンポーネントを、最も基本的なものからより複雑なものまで以下に示します。要素とセグメントは常に必須です。複合、グループ、構造は、ドキュメントの最上位構造に応じて必要になる場合があります。
-
要素 - 要素は基本データ項目です。これには、型と固定幅が関連付けられているほか、データ値の読み書きの方法を示す書式オプションがあります。
-
複合 - (省略可能) 要素のグループ。これには、他の子複合を含めることもできます。
-
セグメント - 反復可能な任意の数の要素または複合で構成される一行のデータ (レコード)。
-
グループ - (省略可能) まとめられた複数のセグメント。これには、他の子グループを含めることもできます。
-
構造 - セグメントの階層構成。これには、データの一部として一意の識別子コードが含まれている必要があります。
FFD ドキュメントの最上位構造
FFD ドキュメントの最上位定義はスキーマの形式から始まります。この場合は、常に「FLATFILE」、「COPYBOOK」、または「FIXEDWIDTH」である必要があります。これらの形式の違いはわずかで、そのほとんどは、Studio での処理方法に関連します。残りは、ファイルに含まれる定義の形式に依存し、次の選択肢があります。
-
単一セグメント - 最上位に直接配置されたセグメント情報 (セグメントの要素または複合の詳細を提供する
values キーを含む)。 -
複数セグメント - 1 つの
segments キーと複数の子オブジェクト。各オブジェクトで 1 つのセグメントを定義します。 -
複数構造 - 1 つの
structures キーと複数の子オブジェクト。各オブジェクトで 1 つの構造を定義します。
単一セグメント
1 つのタイプのレコードのみを使用する場合、FFD ではそのレコードタイプのセグメント定義のみが必要です。
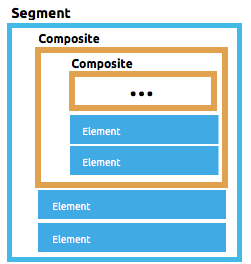
これは 1 つのセグメントのみを持つ単純なスキーマです。
form: FLATFILE
id: 'RQH'
tag: '1'
name: Request Header Record
values:
- { name: 'Organization Code', type: String, length: 10 }
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }上の例では、単一セグメント内で要素のリストを定義しているのみです。これらの要素をまとめる複合はありません。
別の例を次に示します。
form: FIXEDWIDTH
name: my-flat-file
values:
- { name: 'Row-id', type: String, length: 2 }
- { name: 'Total', type: Decimal, length: 11 }
- { name: 'Module', type: String, length: 8 }
- { name: 'Cost', type: Decimal, length: 8, format: { implicit: 2 } }
- { name: 'Program-id', type: String, length: 8 }
- { name: 'user-id', type: String, length: 8 }
- { name: 'return-sign', type: String, length: 1' }単にわかりやすくすることを目的として形式を簡略化しています。1 つの子セグメント定義のみの場合も segments キーを使用できます。
複数セグメント
同じ変換で複数のタイプのレコードを使用する場合、その異なるレコードの組み合わせ方法を制御する構造定義を使用する必要があります。
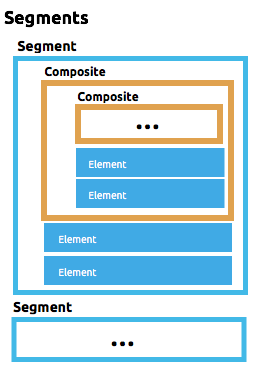
ほとんどの場合、異なるタイプのレコードの識別方法を定義する必要があります。これを行うには、レコード定義の一部として tagValue 項目を識別します。パーサーは、各レコードの項目の内容を確認し、レコードタイプを識別した後、定義された構造にレコードがどのように収められているかを確認します。
複数のコンポーネントレコードタイプを持つ完全な構造スキーマの例を次に示します。
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
...この例は完全ではありません。参照する各セグメントを最後に定義する必要があります。この例でこれらのセグメントを参照する方法については、「参照された定義とインライン化された定義の比較」を参照してください。
複数構造
FFD に複数の構造またはセグメント定義がある場合、スキーマを Transform コンポーネントのメタデータ記述に適用するときに、どれを使用するかを指定する必要があります。
複数構造を持つスキーマの最上位構造は次のようになります。
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
usage: O
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
- id: 'BatchRsp'
name: Batch Response
data:
- { idRef: 'RSH' }
- groupId: 'Batch'
usage: O
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RSF' }
segments:
- id: 'RQH'
...この例では、2 つの異なる構造 (BatchReq 構造と BatchRsp 構造) を定義します。この各構造で特定のセグメント順序およびセグメントグループを使用します。グループ Batch は両方の構造で反復されます。Batch グループは 1 つの BCH 行、複数の TDR 行、および 1 つの BCF 行で構成されます。
この例は完全ではありません。参照する各セグメントを最後に定義する必要があります。この例でこれらのセグメントを参照する方法については、「参照された定義とインライン化された定義の比較」を参照してください。
要素定義
要素定義は、標準特性の基本的なキー-値ペアで構成される、アプリケーションデータの基本構成要素です。フラットファイルスキーマではインライン要素定義が一般的に使用されます。この定義では、各要素がセグメントまたは複合構造内の各要素の使用場所で定義されますが、要素を個別に定義して必要に応じて参照することもできます。参考用に定義したいくつかの要素定義を次に示します。
- { id: 'OrgCode', name: 'Organization Code', type: String, length: 10 }
- { id: 'CreatDate', name: 'File Creation Date', type: Date, length: 8 }
- { id: 'CreatTime', name: 'File Creation Time', type: Time, length: 4 }
- { id: 'BatchTransCount', name: 'Batch Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { id: 'BatchTransAmount', name: 'Batch Transaction Amount', type: Integer, format: { justify: zeroes }, length: 10 }指定された id 値は、セグメントまたは複合の一部としてこれらの定義のいずれかを参照する場合に idRef 値として使用されます。要素をセグメント定義内でインラインで定義する場合 (ドキュメントの最後に要素を定義して参照する方法とは対照的)、id 項目は不要です。
要素定義には次の属性が含まれる可能性があります。これらは、インライン定義、参照された定義 (上の例を参照)、または定義への参照に適用されるものとして、「形式」によって分類されます。
| 名前 | 説明 | 形式 |
|---|---|---|
|
出現数 (省略可能、デフォルトは |
インラインまたは参照 |
|
要素識別子 |
参照された定義 |
|
要素識別子 |
参照 |
|
要素名 (省略可能) |
すべて |
|
値の型コード (以下のリストを参照) |
インライン、または参照された定義 |
|
型固有の書式情報 |
インライン、または参照された定義 |
|
値の文字位置の数 |
インライン、または参照された定義 |
|
セグメントを識別するために使用するこの要素の値 (「スキーマの完全な例」を参照) |
インライン、または参照された定義 |
要素の定義で許可される型を次に示します。
| 名前 | 説明 |
|---|---|
Boolean (ブール) |
ブール値 |
Date (日付) |
年、月、および日コンポーネントを持つ非ゾーン日付値 (一部はテキスト形式で表示されない場合があります) |
DateTime |
年、月、日、時、分、秒、およびミリ秒コンポーネントを持つ非ゾーン日時値 (一部はテキスト形式で表示されない場合があります) |
Decimal (10 進数) |
10 進数値。テキスト形式に明示的な小数点が含まれる場合と含まれない場合があります |
Integer (整数) |
整数値 |
Packed (パック) |
10 進数値のパック 10 進数表現 |
String (文字列) |
文字列値 |
Time (時刻) |
時、分、秒、およびミリ秒コンポーネントを持つ非ゾーン時刻値 (一部はテキスト形式で表示されない場合があります) |
Zoned (ゾーン) |
ゾーン 10 進数 (Cobol 形式) |
値の型では、値のテキスト形式に影響するさまざまな書式オプションがサポートされます。主なオプションと適用先の型を以下に示します。
| キー | 説明 | 適用先 |
|---|---|---|
implicit (暗黙的) |
暗黙的な小数点以下桁数 (テキスト形式で小数点のない固定小数点値で使用されます) |
Decimal (10 進数)、Packed (パック)、Zoned (ゾーン) |
justify (行揃え) |
項目内の行揃え (LEFT、RIGHT、NONE、または ZEROES。ZEROES は数値のみで使用) |
Packed (パック) 以外のすべて |
pattern (パターン) |
数値の場合、解析および書き込み用の |
Date (日付)、DateTime、Decimal (10 進数)、Integer (整数)、Time (時刻) |
署名 |
数値の符号の使用方法 (UNSIGNED、NEGATIVE_ONLY、OPTIONAL、ALWAYS_LEFT、ALWAYS_RIGHT) |
Decimal (10 進数)、Integer (整数)、Zoned (ゾーン) |
signed (符号あり) |
符号ありか符号なしかを示すフラグ |
Packed (パック) |
複合定義
複合は、通常一緒に存在する要素のリストを参照するのに役立ちます。たとえば、firstName と lastName はグループとして参照される可能性があるため、それらをまとめて 1 つの複合にバンドルすることができます。要素を複合にまとめると、リストを反復することもできます。
複合定義は、セグメント定義によく似ており、標準特性のいくつかのキー-値ペアおよび値のリストで構成されます。複合には、要素または他のネストされた複合とインライン化された定義への両方の参照が含まれる可能性があります。複合定義の例を次に示します。
- id: 'DateTime'
name: 'Date/Time pair'
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }複合定義には、次の属性が含まれる可能性があります。
| 名前 | 説明 | 形式 |
|---|---|---|
|
実際の出現数を提供する、包含するレベルからの値 ( |
インライン定義、または参照 |
|
出現数 (または |
インライン定義、または参照 |
|
参照の複合識別子 |
|
|
複合名 (省略可能)。 |
インライン、または参照された定義 |
|
複合内の要素と複合のリスト。 |
インライン、または参照された定義 |
この値リストはセグメント定義の値リストと同じ形式を使用します。
セグメント定義
セグメントはデータ内のレコードのタイプを記述します。セグメントは主に要素と複合の参照または直接定義と、セグメントを記述するいくつかのキー-値ペアで構成されます。少し複雑なスキーマでは、2 つの異なるセグメントを含む構造を使用し、その 1 つのセグメントで部品表の単一ヘッダーに含める項目 (日付、人など) を記述し、もう 1 つのセグメントで部品表内の実際の各項目に含める繰り返し項目を記述することができます。
これは、1 つの簡単な要素と、2 つの要素が入っている複合を含むサンプルのセグメント定義です。
- id: 'RQH'
name: Request Header Record
values:
- { name: 'Organization Code', type: String, length: 10 }
- id: 'DateTime'
name: 'Date/Time pair'
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }セグメント定義には、次の属性が含まれる可能性があります。
| セクション | 説明 |
|---|---|
|
セグメント識別子 (インライン定義では使用せず、参照された定義では必須) |
|
セグメント名 (省略可能) |
|
セグメント内の要素と複合のリスト (インライン化、または参照) |
構造定義
構造定義はセグメントとグループ定義への参照のリスト、および標準特性の一連のキー-値ペアで構成されます。セグメントは、反復する可能性のある一連のセグメントで構成されるグループにさらに整理することができます。
サンプルの構造定義を次に示します。
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
...この例には、最上位の 2 つのセグメント (RQH と RQF) への参照、および他のセグメント (BCH、TDR、および BCF) への参照を含むグループ定義 Batch が含まれます。この構造を機能させるには、参照された各セグメントを定義する必要があります。この例でセグメントを参照する方法については、「参照された定義とインライン化された定義の比較」を参照してください。
構造定義には、次の属性が含まれる可能性があります。
| 構造キー/セクション | 説明 |
|---|---|
|
構造識別子 |
|
構造名 (省略可能) |
|
構造内のセグメント (およびグループ) のリスト |
セグメントリスト内の各項目はセグメント参照 (またはインライン定義) またはグループ定義 (常にインライン) です。
参照された定義とインライン化された定義の比較
最上位形式の選択肢以外にも、構造、セグメント、または複合のコンポーネントを表すことに関して選択肢が用意されています。コンポーネントのセグメント、複合、および要素を使用場所でインラインで定義するか、それらをテーブル内で定義して任意の場所から参照できます。インライン定義のほうがより簡単でコンパクトですが、テーブル形式では定義を再利用できます。テーブル形式の例には id 値を含める必要があり、その定義への各参照で idRef を使用します。次の例は、構造を構成するセグメントにこれを適用する方法を示しています。
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { idref: createDate }
- { idref: createTime }
- { idref: fileId }
- { idref: currency }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { idref: batchCount }
- { idref: transactionCount }
- { idref: transactionAmount }
- { idref: debitCredit }
- { idref: fileId }
elements:
- { id: createDate, type: Date, length: 8 }
- { id: createTime, type: Time, length: 4 }
- { id: fileId, type: String, length: 10 }
- { id: currency, type: String, length: 3 }
- { id: batchCount, type: Integer, format: { justify: zeroes }, length: 4 }
- { id: transactionCount, type: Integer, format: { justify: zeroes }, length: 6 }
- { id: transactionAmount, type: Integer, format: { justify: zeroes }, length: 12 }
- { id: debitCredit, type: String, length: 2 }上の例では、BatchReq 構造は data 定義セクションのセグメントを参照しています。次に、スキーマの最上位の segments セクションでセグメントがそれぞれ定義され、後の elements セクションで定義されている要素を参照しています。
同じ構造のインライン化された定義は次のようになります。
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }
- { name: 'Unique File Identifier', type: String, length: 10 }
- { name: 'Currency', type: String, length: 3 }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { name: 'File Batch Count', type: Integer, format: { justify: zeroes }, length: 4 }
- { name: 'File Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'File Transaction Amount', type: Integer, format: { justify: zeroes }, length: 12 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Unique File Identifier', type: String, length: 10 }スキーマの完全な例
form: FIXEDWIDTH
structures:
- id: 'BatchReq'
name: Batch Request
data:
- { idRef: 'RQH' }
- groupId: 'Batch'
count: '>1'
items:
- { idRef: 'BCH' }
- { idRef: 'TDR', count: '>1' }
- { idRef: 'BCF' }
- { idRef: 'RQF' }
segments:
- id: 'RQH'
name: "Request File Header Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'RQH' }
- { name: 'File Creation Date', type: Date, length: 8 }
- { name: 'File Creation Time', type: Time, length: 4 }
- { name: 'Unique File Identifier', type: String, length: 10 }
- { name: 'Currency', type: String, length: 3 }
- id: 'BCH'
name: "Batch Header Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'H' }
- { name: 'Company Name', type: String, length: 30 }
- { name: 'Unique Batch Identifier', type: String, length: 10 }
- id: 'TDR'
name: "Transaction Detail Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'D' }
- { name: 'Account Number', type: String, length: 10 }
- { name: 'Amount', type: Integer, format: { justify: zeroes }, length: 10 }
- { name: 'Type', type: String, length: 2 }
- id: 'BCF'
name: "Batch Footer Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'BAT' }
- { name: 'Sequence Number', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Batch Function', type: String, length: 1, tagValue: 'T' }
- { name: 'Batch Transaction Amount', type: Integer, format: { justify: zeroes }, length: 10 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Batch Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'Unique Batch Identifier', type: String, length: 10 }
- id: 'RQF'
name: "Request File Footer Record"
values:
- { name: 'Record Type', type: String, length: 3, tagValue: 'RQF' }
- { name: 'File Batch Count', type: Integer, format: { justify: zeroes }, length: 4 }
- { name: 'File Transaction Count', type: Integer, format: { justify: zeroes }, length: 6 }
- { name: 'File Transaction Amount', type: Integer, format: { justify: zeroes }, length: 12 }
- { name: 'Type', type: String, length: 2 }
- { name: 'Unique File Identifier', type: String, length: 10 }この例には、5 個のコンポーネントセグメントを持つ「BatchReq」という名前の 1 つの構造が含まれ、ファイルおよびセグメントのバッチデータの 2 重にネストされた構造を使用しています。各バッチには反復する詳細レコードが含まれています。すべての要素定義がインライン化されています。
BatchReq 構造定義では、データが次のレコードで構成されている必要があります。
-
セグメント
RQH に対応する 1 つのレコード -
セグメント
BCH に対応する 1 つ以上のレコード -
BCH レコードごとに、特定のトランザクションの詳細を提供する 1 つ以上の TDR レコード -
BCH レコードごとに、包含する TDR レコードに続く BCF レコード -
最後に、セグメント
RQF に対応する 1 つのレコード
この例では、各レコードは、tagValue が指定された 3 文字の「Record Type (レコードタイプ)」項目で始まります。バッチレコードの場合、レコードタイプは「Batch Function (バッチ関数)」の tagValue によってさらに指定されます。
スキーマ例に一致するデータのサンプルを次に示します。
RQH201809011010A000000001USD
BAT000001HACME RESEARCH A000000001
BAT000002D01234567890000032876CR
BAT000003D01234567880000087326CR
BAT000004T0000120202CR000002A000000001
BAT000005HAJAX EXPLOSIVES A000000002
BAT000006D12345678900000003582DB
BAT000007D12345678910000000256CR
BAT000008T0000003326DB000002A000000002
RQF0002000008000000116876CRA000000001例内のインラインは、次のように定義された構造に一致します。
-
1
RQH (要求ファイルのヘッダーレコード) 最初の 3 文字の「RQH」値によって識別 -
2
BCH (バッチのヘッダーレコード) 最初の 3 文字の「BAT」値と位置 10 の「H」文字を組み合わせて識別 -
3-4
TDR (トランザクションの詳細レコード) 最初の 3 文字の「BAT」値と位置 10 の「D」文字を組み合わせて識別 -
5
BCF (バッチのフッターレコード) 最初の 3 文字の「BAT」値と位置 10 の「T」文字を組み合わせて識別 -
6
BCH (バッチのヘッダーレコード) 最初の 3 文字の「BAT」値と位置 10 の「H」文字を組み合わせて識別 -
7-8
TDR (トランザクションの詳細レコード) 最初の 3 文字の「BAT」値と位置 10 の「D」文字を組み合わせて識別 -
9
BCF (バッチのフッターレコード) 最初の 3 文字の「BAT」値と位置 10 の「T」文字を組み合わせて識別 -
10
RQF (要求ファイルのフッターレコード) 最初の 3 文字の「RQF」値によって識別
tagValue 項目は高い柔軟性を提供します。上の例では、一部のレコードタイプで単一の tagValue を使用し、他のレコードタイプで 2 番目の tagValue を追加していますが、さまざまなタイプのレコードをパーサーが識別できるように十分な詳細が提供されている限り、tagValue でまったく異なる項目を (または、分離された一連の項目も) 使用することもできます。
古いバージョンのドキュメントでは、構造には tagStart と tagLength 値、セグメントには tag 値を使用して、タグ値に基づく異なる方法でレコードを識別していました。セグメントのこの識別方法は、tagValue の方法よりも非常に多くの制限があり、廃止されました。