Einstein プロンプトの例
いくつかのユースケースと、各状況の Einstein プロンプトの例を次に示します。これらのプロンプトは、各テスト中に使用されるサンプルデータに基づいており、カスタムドキュメントを分析および形成するプロンプトの作成に関するインサイトを提供します。
これらの例は、開始点として使用したり、各自のドキュメントに対してテストしたり、想定される結果を得るまで変更したりできます。
米国の運転免許証の詳細の抽出
次の Einstein プロンプトは、運転免許証 ID ドキュメントのデータを抽出し、情報を JSON 形式で出力します。
-
ドキュメントの例
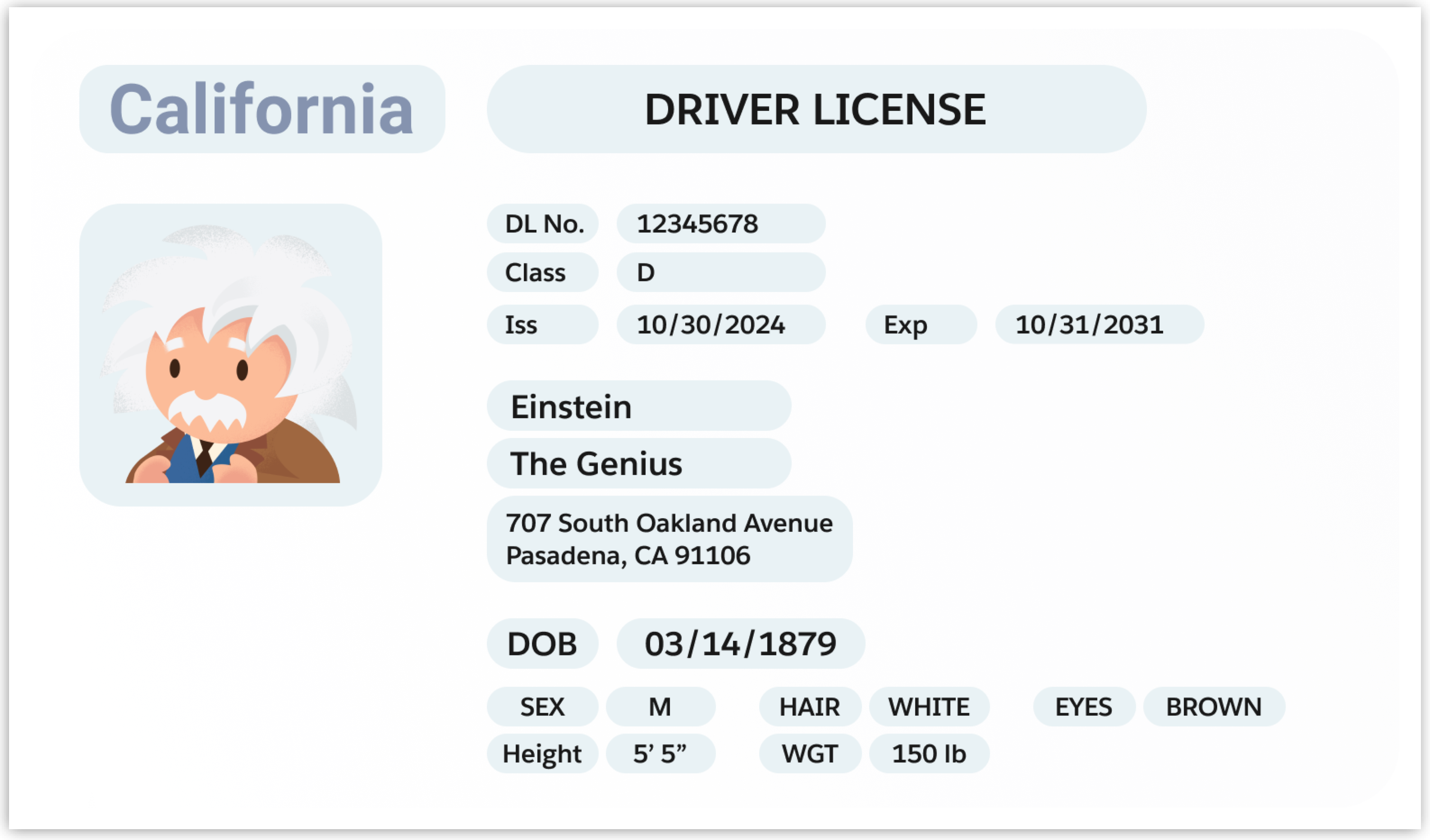
-
プロンプトの例
Identify key elements from the specified document and return them in JSON format. Do not create new information, provide answers only from the text provided. The JSON format is as follows: { "id_data": { "doc_number":<replace with value found for License ID or document ID>, "first_name": <replace with the first name of the person in the text>, "last_name": <replace with the last name of the person in the text>, "issue_date": <replace with the date of issue of this document>, "dob": <replace with date of birth found in the text also represented as dob>, "exp_date": <replace with expiration date, sometimes written as EXP>, "state_region": <replace with state or region where this document was issued>, "height": <replace with height specified if not found, say "not found">, "class": <replace with vehicle classification if found">, "eye_color": <replace with eye color if found">, "sex": <sex as specified>, "weight": <replace with the weight found>, "restrictions":<replace with any restrictions listed in the document>, "address": { "street": <replace with the street line of the address including any apartment numbers>, "city":<replace with the city in the address found>, "state": <replace with the state found in the address>, "zip": <replace with the zipcode found in the address> } } } -
出力
{ "id_data": { "doc_number": "12345678", "first_name": "The Genius", "last_name": "Einstein", "issue_date": "10/30/2024", "dob": "03/14/1879", "exp_date": "10/31/2031", "state_region": "California", "height": "5'5\"", "class": "D", "eye_color": "BROWN", "sex": "M", "weight": "150 lb", "restrictions": "None", "address": { "street": "707 South Oakland Avenue", "city": "Pasadena", "state": "CA", "zip": "91106" } } }
複数ページのドキュメントの分類
この例のソースドキュメントは、複数のエントリがあるタイムシート概要ドキュメントが含まれる、複数ページの PDF です。目標は、各ページの個人の名前を識別してコンテンツを分類することです。この場合、次のプロンプトで個人の名前と対応するページ番号が含まれる JSON 形式のリストが返されます。
-
ドキュメントの例
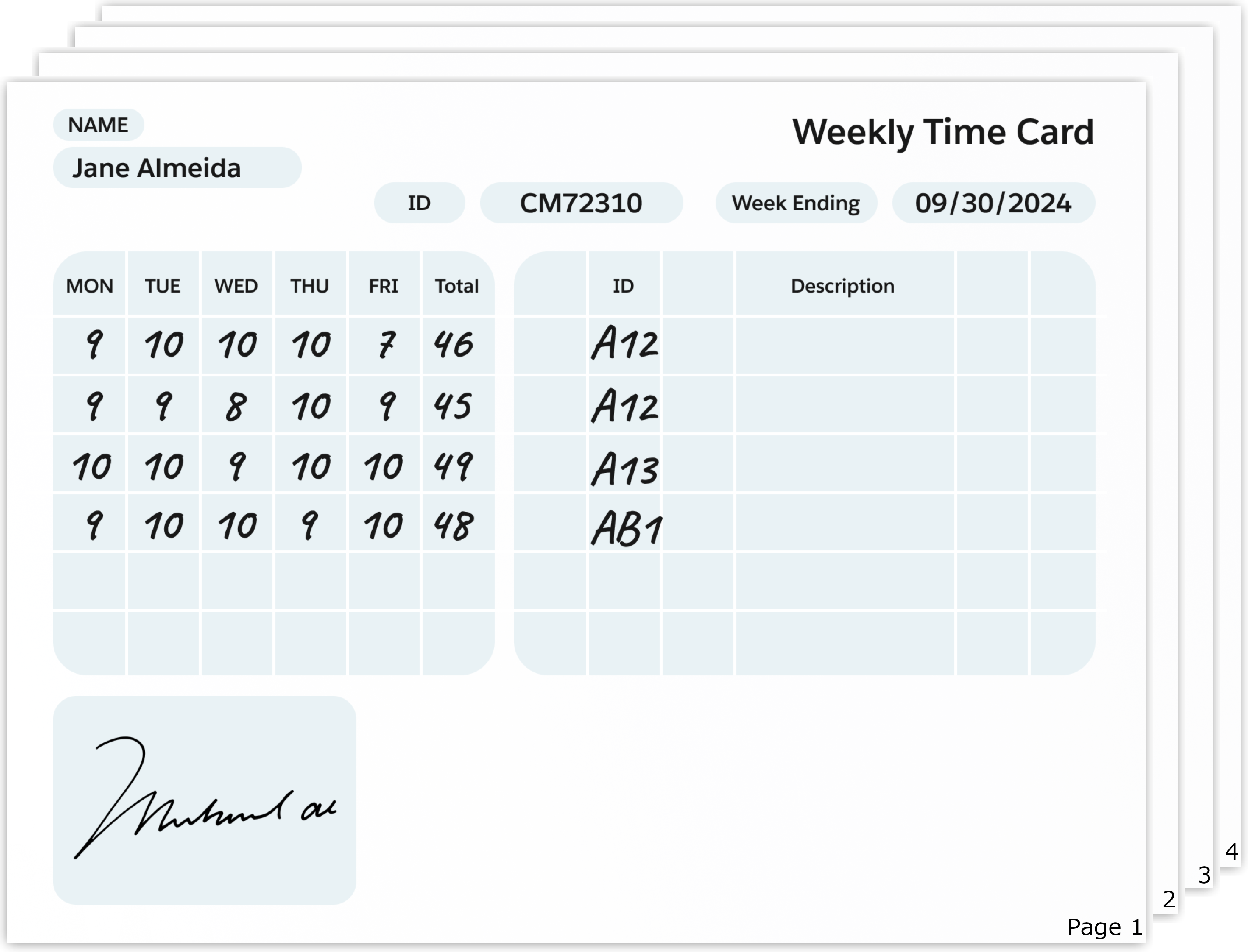
-
プロンプトの例
Classify each page of the following timesheet summary as a unique document type and also identify whether the page continues from the previous document type or it is a new one. Summarize all the employee's names in the timesheet summary document and the pages where their timesheet entry is found. Structure the output as a JSON where the employee name is the key and the page number is the value. -
出力
{ "Jane Almeida": 1, "Charles Montes": 2, "Albert Vignoli": 3, "Max the Mule": 4 }
手書きの値が含まれるフォームデータのキー/値ペアとしての抽出
次の例は、診断書を分析してキー/値ペアとして抽出し、抽出中に筆跡を考慮するプロンプトです。
-
ドキュメントの例
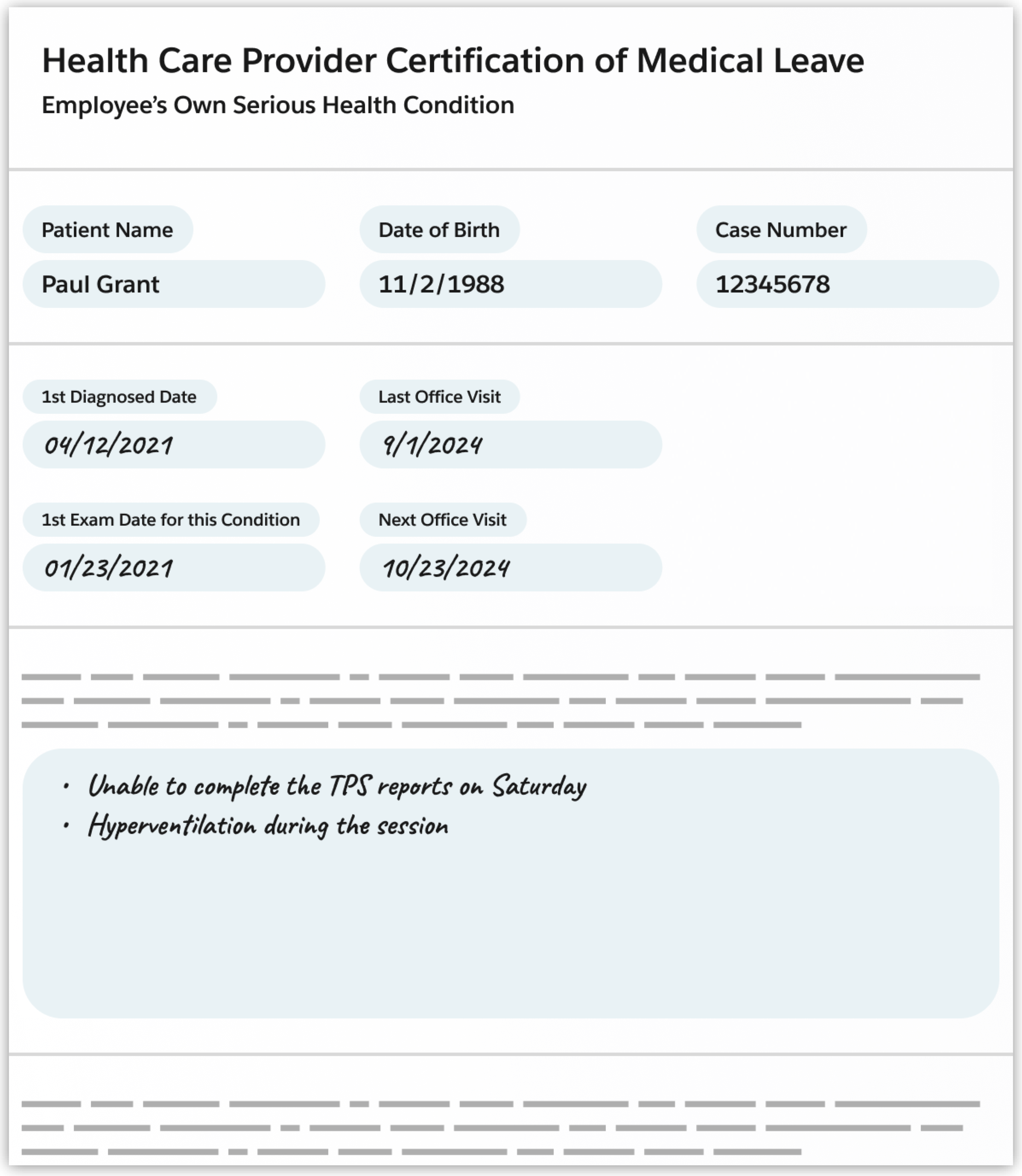
-
プロンプトの例
Analyze this form for a medical leave and extract its values. Don't extract document's title. Present the data as key-value pairs in a JSON formatted response. If you find a date, format it as YYYY/MM/DD. If you find a list of handwritten symptoms, return them as an array and label them "Reason for Absence". Do not create any facts of information, interpret only the information in the document. An example output JSON is: "Patient_Name": { "value": "Paul Grant" } -
出力
{
"Patient_Name": {
"value": "Paul Grant"
},
"Date_of_Birth": {
"value": "1988/11/02"
},
"Case_Number": {
"value": "12345678"
},
"1st_Diagnosed_Date": {
"value": "2021/04/12"
},
"Last_Office_Visit": {
"value": "2024/09/01"
},
"1st_Exam_Date_for_this_Condition": {
"value": "2021/01/23"
},
"Next_Office_Visit": {
"value": "2024/10/23"
},
"Reason_for_Absence": {
"value": [
"Unable to complete the TPS reports on Saturday",
"Hyperventilation during the session"
]
}
}