Batch Job Phases
Each time a Batch Job component executes, it goes through these phases:
-
Load and Dispatch Phase: The Batch Job component splits valid input into records and prepares the records for processing. This phase takes place within the Batch Job component.
-
Process Phase: Mule components and connector operations within one or more Batch Step components in the Batch Job process records within a given batch job instance. Processing within a Batch Aggregator component also occurs in the Process phase.
-
On Complete Phase: The Batch Job component issues a report object with the result of processing the batch job instance.
For an example, see batch phase XML.
Load and Dispatch Phase
When an upstream event in the flow triggers the Batch Job component, the Load and Dispatch phase begins. In this phase, these actions occur:
-
Mule creates a new batch job instance that persists through each phase of a batch job.
Within the scope of the Batch Job component, Mule exposes the currently processing batch job instance ID through the
batchJobInstanceIdvariable. You can usevars.batchJobInstanceIdto access the identifier of the current instance in any batch processing phase. The auto-generated identifier is a UUID, but you can change it to a different value. For details, see Batch Job Instance ID. -
The Batch Job component automatically splits the received message payload into records and stores the records in the stepping queue.
The Batch Job component either successfully generates and queues a record for every item from the input, or the entire event fails with an error type, such as
MULE:EXPRESSIONmessage, and an error message, such as"Expecting Array or Object but got String." evaluating expression: "payload".In Anypoint Runtime Manager, the queue name is prefixed with
BSQ, for example: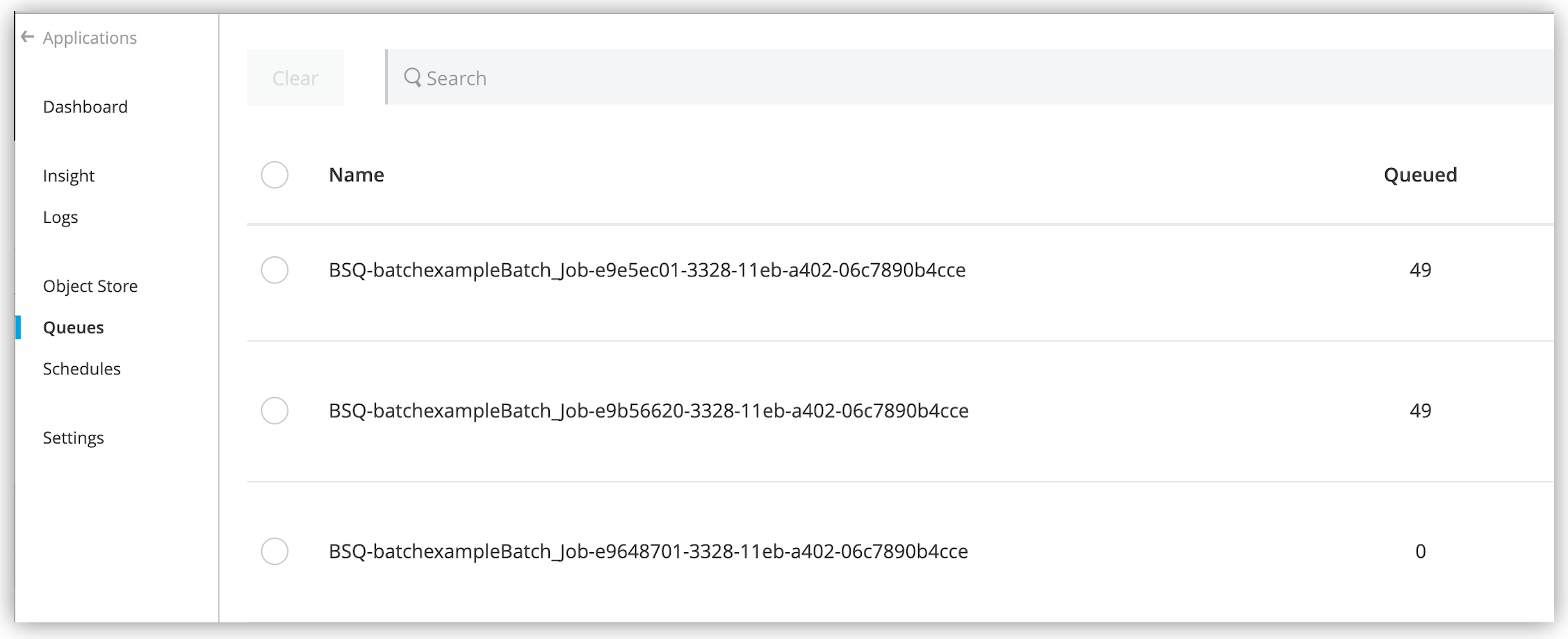
-
The Batch Job component starts the execution of a batch job instance that processes the loaded records.
Process Phase
The Process phase begins after the Load and Dispatch phase finishes loading records to the queue and starts execution of a batch job instance. In this phase, Batch Step components concurrently pull record blocks of the configured size from the queue to process them. (The default batch block size is 100.)
Within the Batch Step component, Mule processes multiple record blocks in parallel by using separate threads, while the records within each block process sequentially by default. Mule uses its auto-tuning capabilities to determine how many threads to use and the level of parallelism to apply (see Execution Engine).
During this phase, processors within the components can access and modify records using the payload and vars Mule variables. The Batch Job component consumes records after all record processing finishes. So any transmission of processed records to an external server or service must take place within the Batch Step or Batch Aggregator components. For Mule variable propagation rules, see Variable Propagation.
After processing records in a block, the Batch Step sends the records back to the stepping queue, where they become available for the next Batch Step component. The next Batch Step doesn’t wait for the previous step to complete. It starts processing available records as soon as they return to the queue. Records are pulled from the queue in blocks, but the composition of these blocks can differ from the previous step because records from different parallel threads are mixed in the queue. At the end of this phase, all records are consumed and aren’t available for further processing by downstream processors in the Mule flow.
Note that since changes to records that take place within a Batch Aggregator component aren’t propagated outside of Batch Aggregator component, changes aren’t visible to subsequent Batch Step components in the flow.
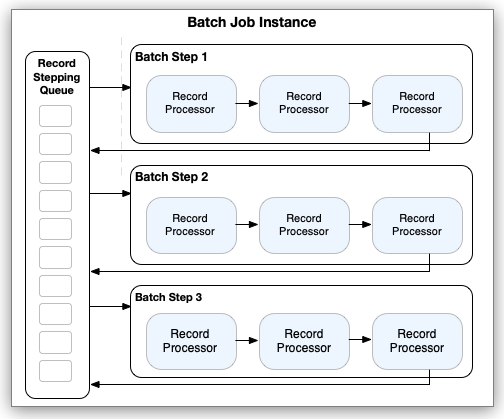
As processing takes place, each record keeps track of all Batch Step components that process it.
By default, a batch job instance doesn’t wait for all its queued records to finish processing in one Batch Step component before making them available for processing by the next Batch Step component. Configuring a Batch Aggregator component changes this behavior:
-
Behavior when the Batch Aggregator component sets a fixed size:
A processor within the Batch Aggregator must be able to receive the array of records as input.
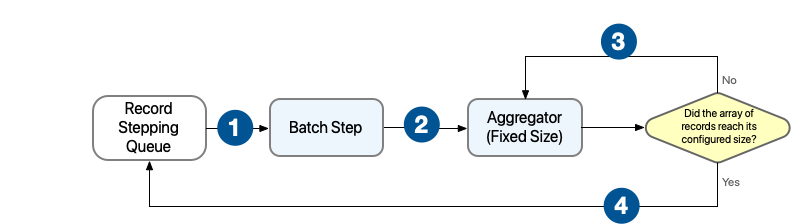
1 Each Batch Step component within a Batch Job component receives one or more record blocks and starts processing them in parallel. 2 After processing a record, the Batch Step component sends the record to the Batch Aggregator component for further processing. 3 When set to process a fixed size ( size), the Aggregator component arranges the records into one or more blocks containing the specified number of records. If fewer records are available than the configured size, the last block of records is smaller.4 After processing records in a given array, the Batch Aggregator component sends all the records back to the stepping queue. -
Behavior when the Batch Aggregator component is configured to stream records:
When streaming, the Batch Aggregator component processes records as soon as it receives them instead of putting them into record blocks. No record is exposed to the next Batch Step component in the flow until all the records in the Aggregator processes all records in the current Batch Step.
A processor within the component must be able to accept an array of records as input.
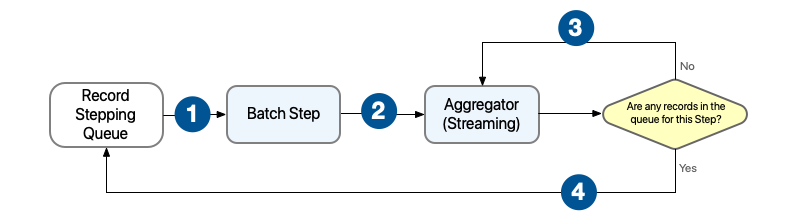
1 Each Batch Step component receives one or more record blocks and starts processing them in parallel. 2 After the Batch Step processes a record, the Batch Step sends the record to Batch Aggregator for further processing. 3 The Batch Aggregator component continues processing records until there are no more records in the stepping queue that are waiting to be processed by the current Batch Step. 4 The Batch Aggregator component sends all the aggregated records to the stepping queue.
Mule retains a list of all records that succeed or fail to process through each Batch Step. If an event processor in a Batch Step fails to process a record, Mule continues processing the batch, skipping over the failed record in each subsequent Batch Step based on the acceptPolicy. The Batch Job component provides the maxFailedRecords property for setting the number records that can fail before the batch job stops. See Batch Job Properties.
On Complete Phase
During this phase, you can configure Mule runtime to create a report or summary of the records it processed in a given batch job instance. This phase provides system administrators and developers insight into which records failed or succeeded, but it doesn’t process or provide access to individual records, nor does it pass processed records to downstream processors in the flow.
At the end of this phase, the batch job instance completes and ceases to exist.
As a best practice, configure a mechanism for reporting on failed or successful records to facilitate further action where required. During the On Complete phase, you can perform either of these tasks:
-
Reference the result object of the batch job instance from elsewhere in the Mule application to capture and use batch job metadata, such as the number of records that failed to process in a particular batch job instance.
-
Log the result object for each batch job instance:
<batch:job name="Batch3">
<batch:process-records>
<batch:step name="Step1">
<batch:record-variable-transformer/>
<ee:transform/>
</batch:step>
<batch:step name="Step2">
<logger/>
<http:request/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger level="INFO" doc:name="Logger"
message='#[payload as Object]'/>
</batch:on-complete>
</batch:job>From the logger set to payload as Object, a report looks something like this:
INFO 2022-07-06 11:39:02,921 [[MuleRuntime].uber.06:
[w-batch-take6].batch-management-work-manager @56978b97]
[processor: w-batch-take6Flow/processors/3/route/1/processors/0;
event: e835b2c0-fd5a-11ec-84a5-147ddaaf4f97]
org.mule.runtime.core.internal.processor.LoggerMessageProcessor:
{onCompletePhaseException=null, loadingPhaseException=null, totalRecords=1000,
onCompletePhaseError=null, elapsedTimeInMillis=117, failedOnCompletePhase=false,
failedRecords=0, loadedRecords=1000, failedOnInputPhase=false,
successfulRecords=1000, inputPhaseException=null,
batchStepResults={firstError=com.mulesoft.mule.runtime.module.batch.privileged.ImmutableBatchStepResult@d9323a5},
processedRecords=10, loadingPhaseError=null, failedOnLoadingPhase=false,
batchJobInstanceId=e84b5da0-fd5a-11ec-84a5-147ddaaf4f97, inputPhaseError=null}
The fields in the batch job report object are accessible as keys when using DataWeave selectors, such as payload.failedRecords to return the number of failed records in the instance.
If you leave the On Complete phase empty, the batch job instance silently completes, and the logs provide processing information about the instance, for example:
Finished execution for instance 'e84b5da0-fd5a-11ec-84a5-147ddaaf4f97' of job 'w-batch-take6Batch_Job'. Total Records processed: 1000. Successful records: 1000. Failed Records: 0