Configuring Horizontal Pod Autoscaling (HPA) for Runtime Fabric Deployments
Runtime Fabric instances support horizontal scaling of Mule app deployments by spinning up additional replicas or spinning down unneeded replicas in response to the CPU usage as a signal.
Mulesoft supports configuring Mule apps to be responsive to the CPU usage on Kubernetes (K8s) runtime side. You can enable CPU based horizontal autoscaling per application on the Runtime Manager application deployment page, which will result in automatic scale up or scale down of the deployment replicas as needed.
In Kubernetes, a Horizontal Pod Autoscaler (HPA) automatically updates a workload resource, with the aim of automatically scaling the workload to match demand. Horizontal scaling means that the response to increased load is to deploy more pods.
| HPA is supported only on Runtime Fabric agent version 2.6.22 and higher. |
This feature applies only to select customers who are opted into the new pricing and packaging model. For more details, see Anypoint Platform Pricing
Before You Begin
To configure autoscaling, the cluster administrator must enable the support for metrics APIs on your managed K8s API server. Refer to your managed vendors documentation on how to install or enable metrics API servers.
Recommendations for Cluster Autoscaling
These recommendations are for your infrastructure team to configure cluster autoscaling
Configure Node Groups
Configure one node group per availability zone, with a minimum of one node in the node group. This ensures that Kubernetes has information about all the availability zones in the cluster and avoids an issue where zone topology unschedulable pod fails to scale-out topologySpread predicate check.
Make sure that nodes from all the node groups have the exact same labels except for the common labels and specific cloud provider labels that are different across nodes or availability zones by default.
Custom labels (which are not common labels and specific cloud provider labels) and are different across nodes need to be excluded from cluster autoscaler when evaluating similar node groups.
For reference on managed EKS labels such as:
eks.amazonaws.com/nodegroup failure-domain.beta.kubernetes.io/region failure-domain.beta.kubernetes.io/zone kubernetes.io/hostname topology.kubernetes.io/region topology.kubernetes.io/zone
Configure Cluster Autoscaler Flags
Start the cluster autoscaler with flag --balance-similar-node-groups=true and exclude the custom labels previously mentioned in the node groups section with the flag --balancing-ignore-label.
These flags ensure that the cluster autoscaler balances the number of nodes across availability zones.
For reference on managed EKS cluster, these node labels are different across node groups:
k8s.amazonaws.com/eniConfigCustom vpc.amazonaws.com/eniConfig
Therefore, the cluster autoscaler starts with:
- --balancing-ignore-label=k8s.amazonaws.com/eniConfigCustom - --balancing-ignore-label=vpc.amazonaws.com/eniConfig
These configuration recommendations serve as a guideline. However, the actual configuration of the cluster autoscaler (CA) depends on the cloud or infrastructure provider (vendor) you use and the relevant topology considerations. You must configure the CA appropriately.
Configure Overprovisioning Nodes
Configure at least one overprovisioning node per availability zone. Each overprovisioning nodes holds a resource that can accommodate three Mule app nodes, which improves the performance when new nodes are needed.
| Refer to your managed vendor documentation for cluster autoscaling best practices and over-provisioning configuration details. |
Configure Topology Spread Constraints
Your Mule app deployments which are enabled with autoscaling, are required to customize the kubernetes resources for the topology spread constraints in pod spec by updating the whenUnsatisfiable field with DoNotSchedule.
This configuration ensures that autoscaling replicas are evenly spread across zones for high availability.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
rtf.mulesoft.com/id: "{{ .Values.id }}"
rtf.mulesoft.com/generation: "{{ .Values.resourceContentHash }}"
Using whenUnsatisfiable: DoNotSchedule guarantees that pods are evenly spread across availability zones. To modify this setting, use the K8S templates CRD to adjust your deployments using HPA to whenUnsatisfiable: DoNotSchedule. You can also use dedicated namespaces (environments) to separate the autoscaling workloads from the classic ones. If you don’t make this change, you use whenUnsatisfiable: ScheduleAnyway.
For further details on the configuration, refer to Customizing Mule App Kubernetes Resources documentation.
Customizing topology spread with whenUnsatisfiable: DoNotSchedule, without the recommended configurations for node groups per availability zone, cluster autoscaler, and overprovisionining, can lead to K8s failing to schedule the replicas with Pending state error.
|
Understand CPU-based Autoscaling Policy
MuleSoft owns and applies the autoscaling policy for your Mule application deployments.
This example shows the CPU-based HPA policy used for Mule apps deployed on Runtime Fabric instances. Note that you can choose minReplicas and maxReplicas values from the Runtime Manager user interface.
Runtime Fabric deploys your Mule apps with Helm. The HorizontalPodAutoscaler resource therefore includes the Helm ownership label and annotations shown in this example. These values allow Helm to recognize and manage the resource as part of the application release. If you manually create or modify the HPA, you must keep these labels and annotations, where <app-name> is the name of your application and <app-namespace> is the environment namespace ID:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
namespace: app-namespace
labels:
app.kubernetes.io/managed-by: Helm
annotations:
meta.helm.sh/release-name: <app-name>
meta.helm.sh/release-namespace: <app-namespace>
spec:
behavior:
scaleDown:
policies:
- periodSeconds: 15
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 1800
scaleUp:
policies:
- periodSeconds: 180
type: Percent
value: 100
selectPolicy: Max
stabilizationWindowSeconds: 0
maxReplicas: <maxReplicasChosenFromRuntimeManagerUI>
metrics:
- resource:
name: cpu
target:
averageUtilization: 70
type: Utilization
type: Resource
minReplicas: <minReplicasChosenFromRuntimeManagerUI>
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
Some points to consider:
Scale up can occur at most every 180 seconds. Each period, up to 100% of the currently running replicas may be added until the maximum configured replicas is reached. For scaling up there is no stabilization window. When the metrics indicate that the target should be scaled up, the target is scaled up immediately.
Scale down can occur at most every 15 seconds. Each Period, up to 100% of the currently running replicas may be removed which means the scaling target can be scaled down to the minimum allowed replicas. The number of replicas removed is based on the aggregated calculations over the past 1800 seconds of the stabilization window.
Min replicas
-
The minimum number of replicas that would be guaranteed to run at any given point of time.
-
Scale down policy would never remove replicas below this number.
Max replicas
-
The maximum number of replicas that are capped, beyond which no more replicas can be added for scale up. For details, see limitations-self.adoc#limitations.
-
Scale up policy would never add replicas above this number.
Enabling HPA can result in customers incurring additional flow usage when your application scales horizontally. To avoid overages from unpredicted scaling, configure the maximum configured replicas judiciously to stay within purchased flow limits. Track your incurred flow usage through usage reports.
HPA uses CPU utilization at average of 70%
HPA bases on resource requests.
When target utilization value is set, the controller calculates the utilization value as a percentage of the equivalent resource request on the containers in each pod.
If pod average use is greater than 70% in a period (periods for scale-up are set as 180 seconds), HPA scales up. Refer to the Kubernetes documentation for additional details.
Performance Considerations and Limitations
For a successful horizontal autoscaling of your Mule apps, review these performance considerations:
-
In Runtime Fabric, the policy in use was benchmarked for Mule apps with CPU Reserved: 0.45vCpu and Limit: 0.55vCpu, which corresponds to these settings:
resources: limits: cpu: 550m requests: cpu: 450m -
Mule apps that scale based on CPU usage are a good fit with CPU based HPA. For example:
-
HTTP/HTTPS apps with async requests
-
Reverse proxies
-
Low latency + high throughput apps
-
Dataweave transformations
-
APIKit Routing
-
API Gateways with policies
-
-
Non-reentrant apps that don’t have built in parallel processing such as batch jobs, scheduler apps without re-entrancy and duplicate scheduling across apps and low throughput, high latency apps with large requests may not be a good fit with CPU based HPA.
-
Scale up and scale down performance can vary based on the replica size and the application type.
-
The policy is optimized for replica sizes with <850m. Larger replica sizes might take longer to scale. HPA is recommended only for smaller CPU applications with average usage of 0.2vCPU.
Configure Horizontal Pod Autoscaling
To configure horizontal autoscaling for Mule apps deployed to Runtime Fabric, follow these steps:
-
Enable the support for metrics APIs on your managed K8s API server.
-
From Anypoint Platform, select Runtime Manager > Applications.
-
Click Deploy application.
-
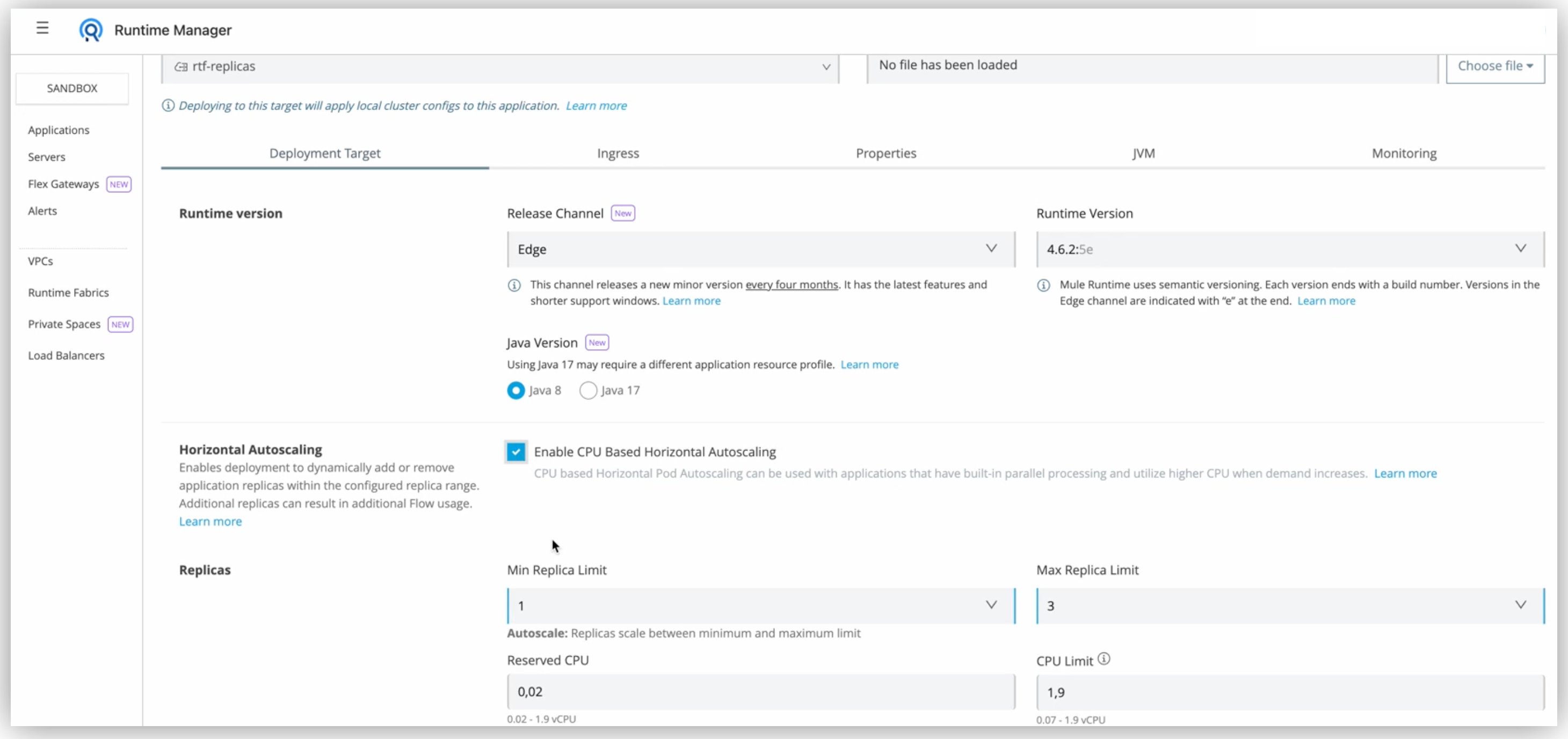
In the Runtime tab, check the Enable Autoscaling box.
-
Set the minimum and maximum Replica Count limits.
-
Click Deploy Application.
Autoscaling Status and Logs
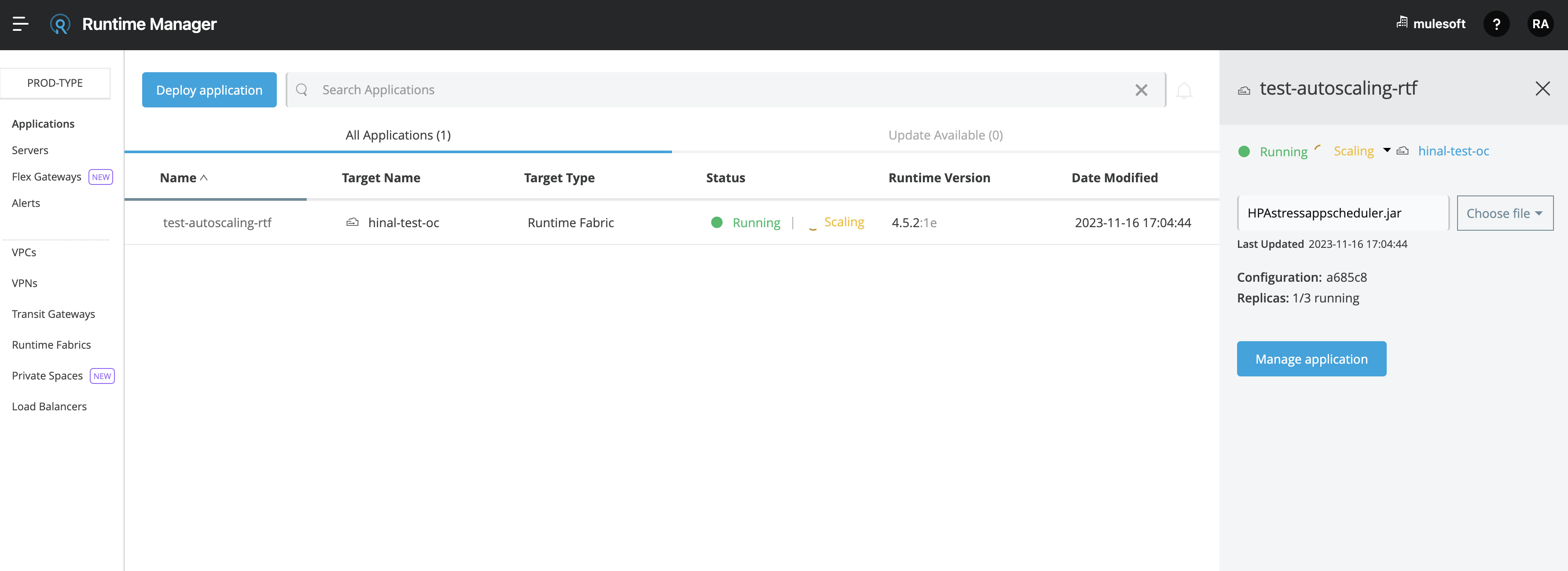
When an autoscaling event occurs and your Mule app with horizontal autoscaling scales up, you can check the Scaling status in the Runtime Manager UI by clicking View status in your application’s details window:
You can also track when autoscaling events occurred through Audit logs in Access Management. Each time an application deployment scaled, there is an audit log published under the product Runtime Manager, by the Anypoint Staff user. The log has Action set to Scaling with the Object as the application ID.

This is an example log payload:
{"properties":{"organizationId":"my-orgID-abc","environmentId":"my-envID-xyz","response":{"message":{"message":"Application id:my-appID-123 scaled DOWN from 3 to 2 replicas.","logLevel":"INFO","context":{"logger":"Runtime Manager"},"timestamp":1700234556678}},"deploymentId":"my-appID-123","initialRequest":"/organizations/my-orgID-abc/environments/my-envID-xyz/deployments/my-appID-123/specs/my-specID-456"},"subaction":"Scaling"}Additionally, you can track the scaled up replicas startup and the number of replicas of your Mule apps by running this kubectl command in your terminal:
kubectl get events | grep HorizontalPodAutoscalerUse the kubectl get events command in Kubernetes to retrieve events that occurred within the cluster. The command provides information about various activities and changes happening in the cluster, such as pod creations, deletions, and other important events.
The grep command filters the output of kubectl get events for lines that contain the string HorizontalPodAutoscaler. This example shows the command output that includes events related to a HorizontalPodAutoscaler with information about successful rescaling operations triggered by the HPA:
# kubectl get events | grep HorizontalPodAutoscaler
5m20s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
5m5s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
4m50s Normal SuccessfulRescale HorizontalPodAutoscaler New size: 10; reason:Troubleshooting
Deployment Fails with invalid ownership metadata Error
When you deploy a Mule app with autoscaling enabled, the deployment can fail and the app shows a Not running status in Runtime Manager with an error similar to this:
1 or more replicas in unexpected state: [Runtime Fabric] UNKNOWN: running helm install:
failed to upgrade: failed to upgrade chart runtime-fabric-public/rtf-mule-chart:<version>:
Unable to continue with update: HorizontalPodAutoscaler "<app-name>" in namespace
"<app-namespace>" exists and cannot be imported into the current release: invalid ownership
metadata; label validation error: missing key "app.kubernetes.io/managed-by": must be set to
"Helm"; annotation validation error: missing key "meta.helm.sh/release-name": must be set to
"<app-name>"; annotation validation error: missing key "meta.helm.sh/release-namespace": must
be set to "<app-namespace>"This error occurs when a HorizontalPodAutoscaler (or another Kubernetes resource, such as a Service or ServiceAccount) with the same name already exists in the namespace but is not owned by Helm because it is missing the required Helm ownership label and annotations. Helm refuses to take ownership of a resource it did not create, so the deployment fails. This commonly happens when:
-
An HPA was created manually or by a tool other than Runtime Fabric.
-
A previous deployment left orphaned resources on the cluster after the application was removed from Runtime Manager, leaving Runtime Manager and the cluster out of sync.
To resolve the error, use one of these options:
-
Add the Helm ownership metadata to the existing resource.
Patch the resource so that Helm can adopt it, where<app-name>is the application name and<app-namespace>is the environment namespace ID:kubectl label horizontalpodautoscaler <app-name> -n <app-namespace> \ app.kubernetes.io/managed-by=Helm --overwrite kubectl annotate horizontalpodautoscaler <app-name> -n <app-namespace> \ meta.helm.sh/release-name=<app-name> \ meta.helm.sh/release-namespace=<app-namespace> --overwrite -
Delete the conflicting resource.
If the resource is left over from a previous deployment, delete it so that Runtime Fabric can recreate it during the next deployment. Verify that the resource is not in use before deleting it:kubectl delete horizontalpodautoscaler <app-name> -n <app-namespace>If the error references a different resource type, such as ServiceorServiceAccount, apply the same option to that resource. When the cluster is out of sync, more than one orphaned resource might be missing the Helm ownership metadata.
After you resolve the conflict, redeploy the application from Runtime Manager.